Die Regression der partiellen kleinsten Quadrate (Partielle Kleinste-Quadrate-Regression, PLS)[1] ist ein Regressionsmodell ähnlich der Hauptkomponentenregression, bei dem die Eingabe iterativ in latente Räume projiziert wird, welche möglichst korreliert mit dem Ausgaberaum sind. Aus diesen Projektionen werden mehrere hierarchisch aufgebaute lineare Regressionsmodelle aufgebaut.
Inhaltsverzeichnis
1Kernidee des Algorithmus
1.1Matrixnotation
2Ergebnis
3Vorteile
4Weblinks
5Einzelnachweise
Kernidee des Algorithmus
Kernidee der Regression der partiellen kleinsten Quadrate. Die Loading-Vektoren im Ein- und Ausgaberaum sind rot gezeichnet (hier zur besseren Sichtbarkeit nicht normiert). Nimmt zu (unabhängig von ), so nehmen und zu.
Betrachtet man gepaarte Zufallsstichproben . als gegeben, so sucht die Regression der partiellen kleinsten Quadrate im ersten Schritt die normierte Richtung , so, dass die Korrelation maximiert wird. Es gilt: mit Korrelationsmatrix im letzten Term und ,
Da die gepaarten Stichproben zufällig aus der gemeinsamen Verteilung gezogen wurden (also gilt), kann der Erwartungswert durch den Stichprobenmittelwert geschätzt werden:
ist Input-Loading-Vektor im -ten Schritt
ist der Output-Loading-Vektor im -ten Schritt
die Projektion ist der Input-Score der Stichprobe
die Projektion ist der Output-Score der Stichprobe
Dieser Artikel oder Abschnitt bedarf einer grundsätzlichen Überarbeitung. Näheres sollte auf der Diskussionsseite angegeben sein. Bitte hilf mit, ihn zu verbessern, und entferne anschließend diese Markierung.
Für den -ten Schritt werden die Daten im Eingaberaum „deflated“ (jedoch nicht im Ausgaberaum) und dann erneut Richtungen , gesucht:
Matrixnotation
Dieser Algorithmus kann in Matrix-Schreibweise dargestellt werden: Dazu werden die Beobachtungen gesammelt in einer Matrix der Dimension (mit der Zahl der Merkmale im Eingaberaum) dargestellt, sodass jede Zeile der Matrix eine Beobachtung darstellt (analog für die Beobachtungen ). Es gilt somit: Für jede Beobachtung gilt nun, dass sie in der Basis der Loading-Vektoren dargestellt werden kann , mit einem Restterm . Für das Matrixelement gilt daher , bzw. für die Matrix:
,
analog für .
Manchmal wird statt der Matrix V auch mit ihrer transponierten gearbeitet, dann gilt:
und
Ergebnis
Nach Auffinden der Loading-Vektoren findet häufig eine Interpretation der Loading-Vektoren sowie der Input-Scores statt.
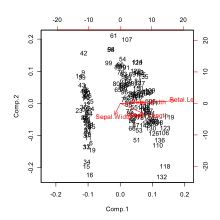
Im Biplot werden die Input-Scores ausgewählter PLS-Schritte dargestellt, z. B. j=1 und j=2 („Component 1“ und „Component 2“ im Bild). Dadurch entsteht eine Punkt-Wolke der Projektionen der (in höheren Schritten durch Deflation modifizierten) Eingabedaten auf die Richtungen . Die Pfeile im Biplot werden durch die Projektionen der künstlichen Daten , und der jeweils korrespondierenden Input-Scores erhalten. Da diese künstlichen Daten jeweils ein Merkmal one-hot encoden, kann ihnen eindeutig ein Merkmal zugewiesen werden, welches im Biplot oft direkt an den Pfeil geschrieben wird.
Biplot als Ergebnis der PLS: die gestreuten Punkte sind die Input-Scores der Beobachtungen. Pfeile zeigen die Beiträge jedes Features zum ersten und zweiten Input-Loading-Vektor
Vorteile
Im Vergleich zur Hauptkomponentenanalyse werden nicht die Richtungen maximaler Varianz im Eingaberaum gefunden, sondern die Richtungen maximaler Korrelation von Ein- und Ausgabedaten. Man könnte sonst beispielsweise x-Variablen eine hohe Gewichtung geben, die eine hohe Varianz besitzen, jedoch gar nicht mit der Zielvariablen korrelieren.
Weblinks
Video: Vorlesung zur Regression der partiellen kleinsten Quadrate von Prof. Harry Asada Ford Professor of Engineering; MIT
Einzelnachweise
↑Svante Wold, Michael Sjöström, Lennart Eriksson: PLS-regression: a basic tool of chemometrics. In: Chemometrics and Intelligent Laboratory Systems. Band58, Nr.2, Oktober 2001, S.109–130, doi:10.1016/S0169-7439(01)00155-1 (elsevier.com [abgerufen am 27. April 2022]).











![{\displaystyle \max _{{\vec {v}}_{j},{\vec {w}}_{j}}E_{{\vec {X}},{\vec {Y}}}[\underbrace {({\vec {v}}_{j}\cdot {\vec {X}})} _{z_{j}}\underbrace {({\vec {w}}_{j}\cdot {\vec {Y}})} _{r_{j}}]=\max _{{\vec {v}}_{j},{\vec {w}}_{j}}{\vec {v}}_{j}E_{{\vec {X}},{\vec {Y}}}[{\vec {X}}{\vec {Y}}]\cdot {\vec {w}}_{j},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb7275fa643927f1bbecea2cb8c50bd0860d8f35)





![{\displaystyle \max _{{\vec {v}}_{j},{\vec {w}}_{j}}{\hat {E}}_{X,Y}[\underbrace {({\vec {v}}_{j}\cdot {\vec {X}})} _{z_{j}}\underbrace {({\vec {w}}_{j}\cdot {\vec {Y}})} _{r_{j}}]=\max _{{\vec {v}}_{j},{\vec {w}}_{j}}{\frac {1}{n}}\sum _{i=1}^{n}[\underbrace {({\vec {v}}_{j}\cdot {\vec {x_{i}}})} _{z_{i,j}}\underbrace {({\vec {w}}_{j}\cdot {\vec {y_{i}}})} _{r_{i,j}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c0a626b76cc762498ae2ba8e804543f554386c9)